Emre Ugur
Ph.D.
CMPE540 Principles of Artificial Intelligence
Project 2
Announced: 2nd of March, 23:59
Due: 16th of March, 23:59
Download
- Please download p2.tgz and implement your algorithms within this framework.
- Bug fix: int State::evaluate() function has no return value. You should replace it with the following code:
int State::evaluate (){
if (isBasicEval)
return basicEvaluate();
else
return novelEvaluate();
}
- Bug fix: int State::evaluate() function has no return value. You should replace it with the following code:
Submission Instructions
- Please follow these instructions, otherwise you will significant points.
- The project will be automatically evaluated. Still you need to prepare a very short report. See the end of this document (or click here) for more information about what I expect in the report.
- Name your report as student-id.pdf. e.g.: 2014301162.pdf
- Copy this report into p2/ directory.
- Create an archive. Name it student-id.tgz with the following command.
$ tar -czvf 2014301162.tgz p2/
- Attach the archive file to an email and send it to emre.ugur@boun.edu.tr with the following subject line: "[CMPE540 Project 2]"
Late submission
The policy is as it was defined before: - (8 x days)Discussion and cheating
I don't like this section, but still should write about this.. You are welcome to discuss the topics about the project. But please do not cheat. There are programs that can automatically check the similarity of the source code and/or execution. Read the department policy about what is considered as cheating. If I am convinced that you cheated, then you will get F.Questions about the project
- The details will be explained in the lecture on 1st of November.
- Please warn me as soon as you see a mistake through email or mailing-list.
- In case you have questions, please send them to the mailing-list so that
- Everybody can see the answer to that question
- People other than me can reply the questions as well
Acknowledgements
This project is adapted from CS188 Berkeley course malterialProject objectives
In this project, you will- implement minimax, alpha-beta prunning, expectiminmax, and
- improve the evaluation function
Introduction to the problem
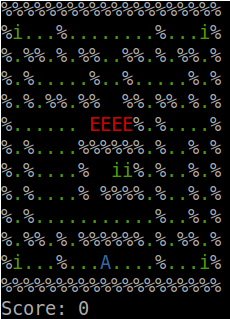
- The environment includes:
- A: Your agent, i.e. good guy
- E: A number of other agents, i.e. bad guys or enemies enemies have indices in the layout files.
- . : Food
- i: Invisibility cloak
- In each step, first good guy moves, then each bad guy moves in sequence.
- If good guy and one enemy are in the same cell, good guy dies.
- If good guy consumes all the food, good guy wins.
- If good guy puts on the invisibility cloak, he will be invisible for 40 steps. So he cannot be seen or killed by the bad guys. In each step, score of the good guy changes as follows:
-
-1 even there is no movement
- +10 if good guy consumes food
- +200 if good guy puts on invisibility cloak
- +500 if good guy consumes all food
- -500 if good guy and enemy are in the same location.
- The game ends if
- Good guy consumes all food: Win!
- Good guy is killed: Lose!
- The objective is to win the game as quick as possible
Compilation
- If your linux terminal does support colored output (many of them do), compile with make
- Colored output in the terminal looks nice when you print-out the solution:
- If the terminal does not support coloring, compile with make NO_COLOR=1
Execution
- Execution command line arguments are provided if you make a mistake in use
- Simply type "./p2 -help" which is a mistake :).
./p2 -enemy RAND/ATTACK -seed
-steps -search RAND/MINIMAX/ALPHABETA/EXPECTIMINIMAX -depth -eval BASIC/NOVEL -layout -update
-enemy for enemy behavior-seed for pseudo-random (-1 or 0 for random seed)
-steps for playing (-1 for play until end)
-search for search algorithm
-depth for search max depth
-eval for state evaluation function
-layout for layout file
-update for update speed in printing the solution path (no printing if -1)
Warming up
- Agent:
- Two search strategies are implemented for you:
- Good guy makes random moves with -s RAND
- Bad guys make random moves with -e RAND
- Bad guys make attacks to the good guy with -e ATTACK
- Run the following command and see some action:
./p2 -enemy RAND -seed -1 -steps -1 -search RAND -depth 1 -eval BASIC -layout layouts/trickyClassic.lay -update 1000
- In order, with these command line arguments, the program selects random actions for enemy, sets a random seed, plays until game ends, selects random actions for good guy, sets search depth to 1 (not used), uses BASIC evaluation (not used), uses the corresponding layout and displays the environment with 1000 msec updates.
Q1: Minimax (4pt)
Implement Agent::miniMaxDecision() method.Your minimax agent should work with any number of enemies, so you'll have to write an algorithm with a minimax tree that have multiple min layers for every max layer.
Your code should also expand the game tree to an arbitrary depth (-d
in command line arguments). This argument sets Agent::maxDepth. Each depth increase corresponds either move of the good guy (MAX node) or moves of the bad guys (all MIN nodes). For example, Depth 1 search involves only the move of the good guy. Depth 2 search involves good guy's move and moves of all bad guys. Depth 3 involves guy's move, moves of all bad guys, and the next move of the good guy. Score of a state is automatically calculated in State::evaluate() function. Basically, it uses the same scoring scheme with agent's scoring defined above.
./p2 -enemy RAND -seed -1 -steps -1 -search MINIMAX -depth 1 -eval BASIC -layout layouts/trickyClassic.lay -update 1000Grading: I will be checking your code to determine whether it explores the correct number of game states and whether computed minimax value is correct. These are the only way reliable ways to detect some very subtle bugs in implementations of minimax. As a result, the autograder will be very picky about how many times you call State Environment::getNextState ( ). If you call it any more or less than necessary, the autograder will complain. The grading will be done based on printed out- Minimax:
- nTimesExpanded:
- selectedAction:
- I generally run enemies in RAND mode while grading. You can use ATTACK mode to see the behavior of the good guy in front of some smarter enemies.
- The minimax values of the initial state in the minimaxClassic layout are 9, 8, 7, -493 for depths 2, 4, 6 and 8 respectively. Depth 8 will be slow (2 mins in my PC).
- The nTimesExpanded values of the initial state in the minimaxClassic layout are 2, 4, 6, 8 digits for depths 2, 4, 6, and 8, respectively in my implementation.
- On larger boards such as openClassic and mediumClassic (the default), you'll find the good guy to be good at not dying, but quite bad at winning. He'll often thrash around without making progress. He might even thrash around right next to a dot without eating it because he doesn't know where he'd go after eating that dot. Don't worry if you see this behavior, the last question 5 will clean up all of these issues.
- When the good guy believes that his death is unavoidable, he will try to end the game as soon as possible because of the constant penalty for living. Sometimes, this is the wrong thing to do with randomly moving enemies, but minimax agents always assume the worst:
./p2 -enemy RAND -seed -1 -steps -1 -search MINIMAX -depth 6 -eval BASIC -layout layouts/trappedClassic.lay -update 1000
- Note that I will not be looking for the exact values , but will check out if the values are close to the correct values.
Q2: Alpha-Beta Pruning (4pt)
- Implement int Agent::alphaBetaDecision() method.
- Make a new agent that uses alpha-beta pruning to more efficiently explore the minimax tree. Again, your algorithm will be slightly more general than the pseudo-code in the textbook, so part of the challenge is to extend the alpha-beta pruning logic appropriately to multiple minimizer agents.
- You should see a speed-up (perhaps depth 6 alpha-beta will run as fast as depth 4 minimax). Ideally, depth 6 on smallClassic should run in just a few seconds per move or faster.
./p2 -enemy RAND -seed -1 -steps -1 -search ALPHABETA -depth 6 -eval BASIC -layout layouts/smallClassic.lay -update 1000Grading:- Because we check your code to determine whether it explores the correct number of states, it is important that you perform alpha-beta pruning without reordering children. In other words, successor states should always be processed in the order returned by Environment::getPossibleActions () . Ordering (and name) of the actions is as follows: MOVE_UP, MOVE_DOWN, MOVE_LEFT, MOVE_RIGHT, NO_MOVE.
- The grading will be done based on printed out values of
- Minimax:
- nTimesExpanded:
- selectedAction:
- The AlphaBetaAgent minimax values should be identical to the MinimaxAgent minimax values, although the actions it selects can vary because of different tie-breaking behavior. Again, the minimax values of the initial state in the minimaxClassic layout are 9, 8, 7 and -493 for depths 2,4,6, and 8, respectively.
- The nTimesExpanded values of the initial state in the minimaxClassic layout are 2, 4, 5, 6 digits for depths 2, 4, 6, and 8, respectively in my implementation.
- Do not use the function definitions below, which were provided in the first version of p2.tgz, in alpha-beta pruning.
- int minValue (int index, State *state, int &alpha, int &beta, int depth);
- int maxValue (int index, State *state, int &alpha, int &beta, int depth);
- In other words, define your own minValue()/maxValue() functions.
Q3: Expectiminimax (4 pt)
- Implement int Agent::expectiMiniMaxDecision()
- Randomly moving enemies are of course not optimal minimax agents, and so modeling them with minimax search may not be appropriate. With this search the good guy will no longer take the min over all enemy actions, but the expectation according to your agent's model of how the enemy act. To simplify your code, assume you will only be running against enemies with -e RAND, i.e. randomly moving enemies.
- The grading will be done based on the performance of good guy in the game and the values
- Minimax:
- nTimesExpanded:
- selectedAction:
- You should now observe a more cavalier approach in close quarters with enemies. In particular, if the good guy perceives that he could be trapped but might escape to grab a few more pieces of food, he'll at least try. Investigate the results of these two scenarios:
./p2 -enemy RAND -seed -1 -steps -1 -search ALPHABETA -depth 6 -eval BASIC -layout layouts/trappedClassic.lay -update 1000./p2 -enemy RAND -seed -1 -steps -1 -search EXPECTIMINIMAX -depth 6 -eval BASIC -layout layouts/trappedClassic.lay -update 1000
- You should find that good guy with EXPECTIMINIMAX wins sometimes (at least 2 out of 10 in my case), while good guy with ALPHABETA loses almost all the times.
- Two search strategies are implemented for you:
Q4: New evaluation function (4 pt)
- Implement int State::novelEvaluate().
- Write a better evaluation function for the good guy in the provided function. You may use any tools at your disposal for evaluation.
- With depth 4 search, your evaluation function should clear the smallClassic layout with two enemies more than half the time within 100 steps
./p2 -enemy RAND -seed -1 -steps 100 -search EXPECTIMINIMAX -depth 4 -eval NOVEL -layout layouts/smallClassic.lay -update 1000
- One way you might want to write your evaluation function is to use a linear combination of features. That is, compute values for features about the state that you think are important, and then combine those features by multiplying them by different values and adding the results together. You might decide what to multiply each feature by based on how important you think it is.
- I will run your agent on the smallClassic layout 10 times. +1 pt if your agent receives an average score of at least 750 (including the scores on lost games).
Report
Include the following in your report:- First name, last name, id
- Q4: Describe your evaluation function in detail. Be as formal as possible.